OpenMP를 이용한 병렬 처리 기법은 다양한 방법이 있습니다. 그중 반복문의 병렬화 방법에 대하여 글을 쓰려합니다. 다른 기법들은 간단히 익혔으나, 실제로 OpenMP를 사용하기에 적합한 방법은 parallel for이고, 그 외의 방법은 딱히 사용처가 없거나, 일반 thread를 이용한 병렬 처리가 더 효율적이라고 생각하거든요. 그럼 큰 의미 없는 인트로는 여기까지 하고, 바로 예제를 통해 병렬 처리를 설명하겠습니다.
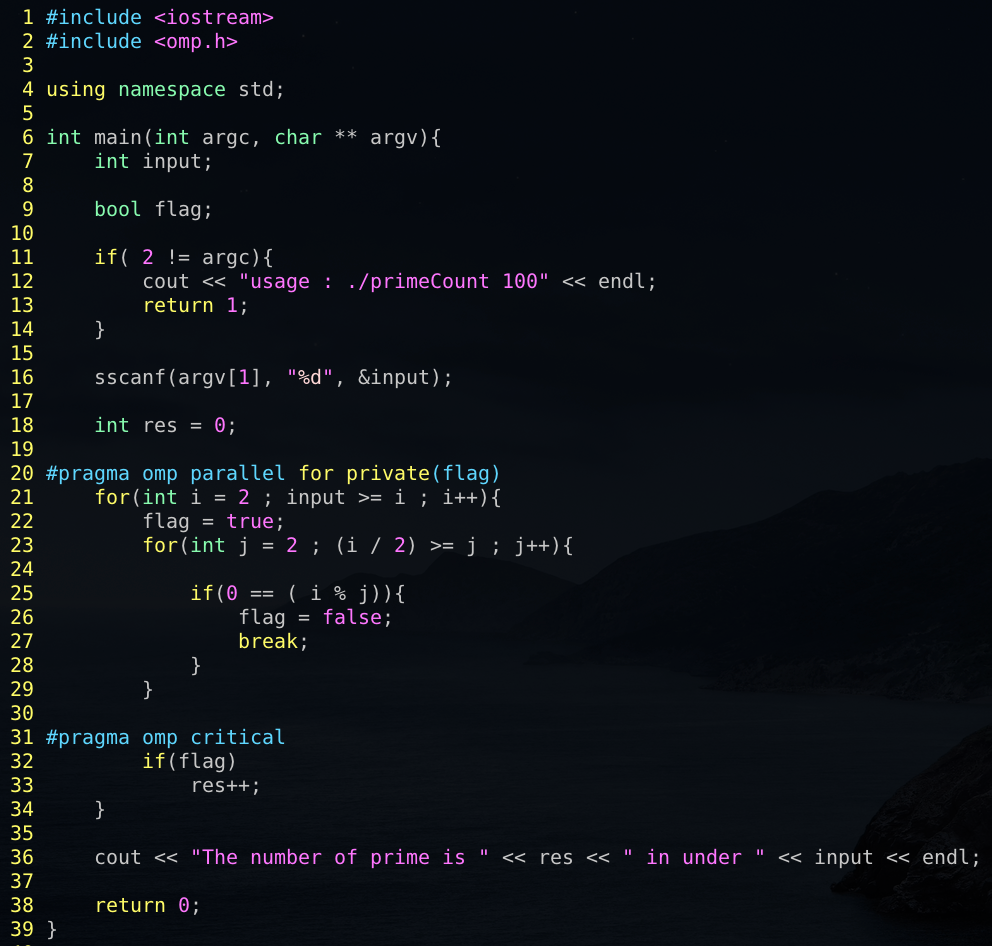
이번 글에서 사용한 예제는 아래 스냅샷과 같습니다. 프로그램의 목적은 입력된 변수보다 작거나 같은 소수(prime number)의 개수를 세는 프로그램입니다. 이 알고리듬은 소수의 정의인 자신보다 작은 두 개의 자연수 곱으로 자신을 만들 수 없다는 특징을 이용한 알고리듬입니다. 이 프로그램은 상당히 효율이 안좋은 프로그램입니다. 실제로 여러 수학과 프로그래밍 기술을 적용하면, 훨씬 고효율의 프로그램을 만들 수 있습니다.

이 부분은 위 프로그램을 설명하고 있으니 쉽게 이해하신 분은 다음으로 넘어가시면 됩니다. 프로그램의 14번째 줄까지는 프로그램이 정상적으로 구동되었는지 확인합니다. 이 프로그램은 구동 시 한 개의 자연수 파라미터 input을 받아야 합니다. 프로그램은 input 보다 작거나 같은 소수 개수를 세고 출력합니다. 16번째 줄은 입력받은 파라미터를 int 변수 input에 저장합니다. 계산 결과는 18번째 줄에서 선언된 res 변수에 저장됩니다.
20번째 줄이 OpenMP의 키워드 입니다. 이 키워드 아래 나오는 for문은 병렬 처리되어 구동됩니다. 21번째 줄부터는 2부터 input까지의 변수 i가 소수인지 판단하여 소수면 res를 증가시킵니다. 35번째 줄에서 결과를 출력하고 프로그램이 종료됩니다.
이렇게 프로그램을 만드셨다면 compile 해야겠죠. OpenMP를 이용한 프로그램을 컴파일할 때는 -fopenmp를 붙여 주시면 됩니다. 명령어는 아래와 같습니다. 리눅스와 mac에서의 컴파일 키워드입니다. 윈도(비주얼 스튜디오)는 제가 경험이 적어서 다른 분들의 글을 링크하려고 했으나 마음에 드는 게 없네요. 구글링으로 처리하시기 바랍니다.
for linux
g++ -fopenmp -o [execute file name] [source code file name]
for mac osx
g++ -Xpreprocessor -fopenmp -lomp -o [execute file name] [source code file name]추가 팁으로 리눅스(우분투)에서는 "sudo apt-get install libomp-dev" 맥에서는 "brew install libomp"로 설치하시면 됩니다. mac에서 brew 설치법은 링크해 두겠습니다.
2020/10/12 - [Mac] - Mac 에 Brew 설치하기 (Catalina)
Mac 에 Brew 설치하기 (Catalina)
Mac을 이용하다 보면 open source 프로그램에 대한 필요성이 발생하게 되죠. Ubuntu 에서 apt-get, centos에서 yum을 이용해 각종 패키지를 설치하는 것과 같이요. 이럴땐 필요한 패키지를 관리하는 사이트�
sbinroom.tistory.com
그럼 다시 OpenMP 이야기로 돌아오죠. 상기 코드와 같은 구조 OpenMP의 키워드 구조는 높은 장점을 가지고 있습니다. 바로 설정된 키워드가 OpenMP 설정 없이 컴파일되면 일반 시리얼 프로그램으로 컴파일되는 것입니다. 이건 다른 병렬 처리 기술? 언어? 툴킷? 적절한 한국어 용어를 모르겠네요. (Cilk+, TBB)에는 없는 큰 장점입니다. 예시로 위 코드는 아래와 같이 두 가지 방식으로 컴파일하였습니다. 빨간 박스 안의 코드는 OpenMP의 키워드를 무시하고 시리얼 프로그램으로 컴파일됩니다. 보라색 박스는 OpenMP의 키워드가 적용되어 for 루프가 병렬화 됩니다.

그럼 컴파일된 코드를 구동해서 시간차이를 봐야겠죠. 컴파일된 코드를 8 코어의 i9 cpu를 가진 맥북에서 구동시킵니다. (하이퍼 스레딩으로 인해 터미널에서는 16 코어로 인식됩니다.) 아래 스냅숏의 왼쪽은 시리얼 프로그램, 오른쪽은 패러렐 프로그램입니다. 보라색 박스 안에 구동 시간을 보면 시리얼 프로그램은 32.802초가 소요되었고, 패러렐 프로그램은 13.308초 걸렸습니다. (시리얼 프로그램 소요시간) / (패러렐 프로그램 소요시간)으로 효율을 계산하면 2.46배 속도가 상승했음을 확인할 수 있죠.

하지만 축배를 들기엔 너무 이르네요. 붉은색 박스를 보시면 결과가 다릅니다. 병렬 처리된 패러렐 프로그램과 시리얼 프로그램의 결과가 다르면 아주 아주~~~~~~~~~ 높은 확률로 패러렐 프로그램이 잘못된 것입니다. 위 프로그램에서 문제는 두 가지 변수에서 발생합니다. 그건 flag와 res입니다. 해당 디버그에 대하여 원래 이 글에 계속 작성 중이었으나, 너무 길어져서 자세한 설명은 다음 글로 올리겠습니다.
솔루션은 아래 스냅샷과 같습니다. private 키워드와 critical 키워드를 이용했죠. 이 부분에 대한 자세한 설명은 다을 글에서 이어 가겠습니다. 결과를 보면 시리얼 프로그램과 같은 결과를 보여줌을 보실 수 있습니다. 이 내용과 방지 방법 또한 다음 글에서 기재하겠습니다.

2020/10/19 - [Computer & Parallel Processing] - OpneMP 병렬 처리 : 공유변수 문제 (레이스 컨디션)
OpneMP 병렬 처리 : 공유변수 문제 (레이스 컨디션)
2020/10/13 - [Computer & Parallel Processing] - OpenMP를 이용한 병렬 처리 (parallel for) OpenMP를 이용한 병렬처리 (parallel for) OpenMP를 이용한 병렬 처리 기법은 다양한 방법이 있습니다. 그중 반복문..
sbinroom.tistory.com
마지막으로 실제로 구동해서 결과를 직접 보실 수 있도록 완성된 코드를 공유합니다. 만약 이 글을 보고 계신 여러분이 소수의 개수를 세는 과제를 하고 계시다면, 주의하세요. 이 글은 공개되어 있으니 같은 강의실에 있는 다른 분도 보고 계실 거예요. 수많은 리포트와 시험 답안지를 채점해 본 입장에서 같은 시드의 코드는 무슨 짓을 하든 중복된 점이 아주 쉽게 보입니다. 과제는 스스로...
#include <iostream>
#include <omp.h>
using namespace std;
int main(int argc, char ** argv){
int input;
bool flag;
if( 2 != argc){
cout << "usage : ./primeCount 100" << endl;
return 1;
}
sscanf(argv[1], "%d", &input);
int res = 0;
#pragma omp parallel for private(flag)
for(int i = 2 ; input >= i ; i++){
flag = true;
for(int j = 2 ; (i / 2) >= j ; j++){
if(0 == ( i % j)){
flag = false;
break;
}
}
#pragma omp critical
if(flag)
res++;
}
cout << "The number of prime is " << res << " in under " << input << endl;
return 0;
}'Computer & Parallel Processing' 카테고리의 다른 글
| OpenMP 병렬 처리 : 스케줄링 (0) | 2021.03.19 |
|---|---|
| OpenMP 병렬 처리 : 공유변수 문제 (레이스 컨디션) 해결 (0) | 2021.03.12 |
| OpenMP 병렬 처리 : 공유변수 문제 (레이스 컨디션) (0) | 2020.10.19 |
| 컴퓨터 사용의 목적 (0) | 2020.10.08 |



